
A mesterséges intelligencia kutatása egyre lenyűgözőbb eredményeket, gyakorlatban is használható megoldásokat hoz. A nagy nyelvi modellekhez (LLM) kötődő kétségtelen fejlődés mellett azonban nem árt a technológia határaival, limitációjával is tisztába lenni.
Erre próbált rámutatni Vladimir Prelovac szoftvermérnök GitHubon elérhető projektjével. Az LLM Chess Puzzles segítségével sakkfeladványokkal lehet teszteli a különböző gyártók által kiadott nagy nyelvi modelleket. Ezek lényege, hogy egy adott állásból a lehető legkevesebb lépéssel kell mattot adni a gyengébb helyzetben lévő oldalnak. Ahogy az az alábbi táblázatból látszik, a generatív algoritmusok alig-alig tudtak jó választ adni.
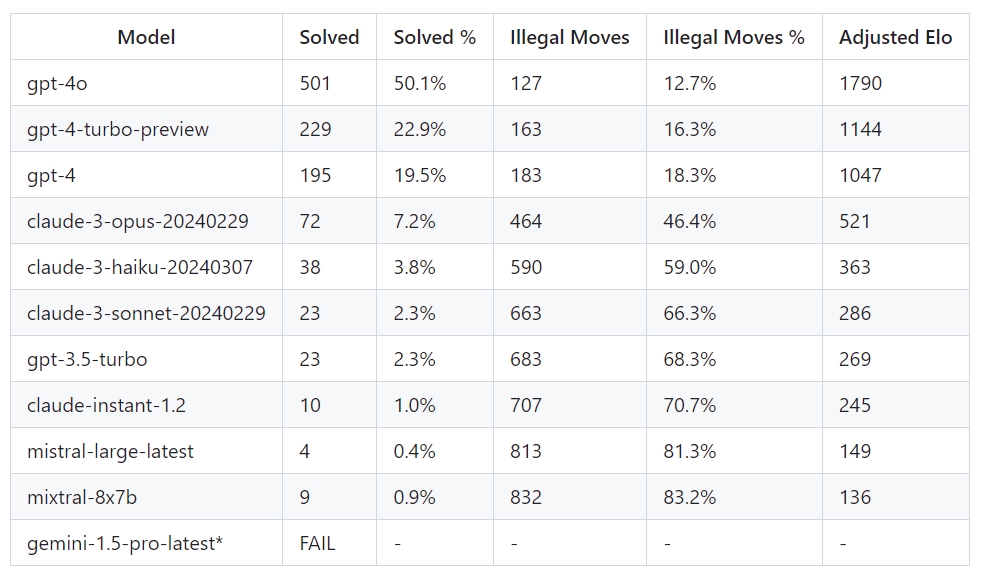
LLM-ek teljesítménye és becsült játékereje az 1000 sakkfeladványból álló teszten (forrás: LLM Chess Puzzles)
A legtöbb megoldás egészen gyalázatosan teljesített. A Google Geminije például teljesen értékelhetetlen volt, mivel az algoritmus semmiféle prompt megadására nem volt hajlandó egy sakklépéssel válaszolni. De a többi modell sem brillírozott: az OpenAI fejlesztéseit kivéve egyik szereplő sem tudott 10 százalék feletti helyes választ adni, sőt az esetek többségében még a sakk legalapvetőbb szabályait sem sikerült betartani. A rangsorolásban negyedik helyen végzett, az iparági benchmarkok alapján kitűnő képességű Claude 3 Opus is majdnem a válaszok felében szabálytalan lépést adott meg.
Prelovac igyekezett a sakktudást megtestesítő Élő-pontra is átszámítani a gépek játékerejét. A fentiek alapján azonban nem meglepetés, hogy az algoritmusok többsége még egy átlagos amatőr játékos szintjét sem tudta megközelíteni. Az összességében kiemelkedően teljesítő, alig néhány héttel ezelőtt debütált GPT-4o a feladatok felét helyesen válaszolta meg, és válaszai alapján már egy erősebb amatőr játékosnak lehetne megfeleltetni. Ennek ellenére még ez a modell is képes volt sok esetben teljesen abszurd, illegális lépéseket megadni. Ilyesmit viszont a szabályokkal csak alapszinten tisztában lévő emberek sem nagyon követnének el.
Hasznosak, de nem okosak
A teszt megalkotója a Registernek nyilatkozva elmondta, hogy az eredmények "kissé kiábrándítóak", de várható volt, hogy ezek a modellek nem boldogulnak a valódi gondolkodást, érvelést, értelmezést igénylő feladatokkal. Tehát attól, hogy bizonyos célfeladatokat sokkal jobban és gyorsabban megoldanak, mint az emberek, még nem válnak általános értelemben intelligensekké.
Mindezt csak alátámasztott Prelovac egy másik kísérlete, amelyben a magyarul 4 a nyerő néven ismert játékkal tesztelte az LLM-eket. A sakknál jóval egyszerűbb játék totális kapitulációra kényszerítette a gépeket. Többszöri finomítás és próbálkozás után itt is a GPT-4o került ki győztesként, ám még ez a modell is csak nagyjából egy négyéves gyerek képességeit tudta produkálni. A szoftvermérnök mindezt annak tudja be, hogy az algoritmusok trenírozására szánt adatkészletekben erről a játékról lényegesen kevesebb információ szerepelt, mint a jóvan népszerűbb sakk esetében.
Nemrégiben számoltunk be róla, hogy a generatív MI a véletlenszámok kiválasztásában sem jeleskedik. Ebben ugyanakkor nem voltak rosszabbak az embereknél, mivel a matematikailag nem megfelelő mintázatok pont azért rajzolódtak ki, mert a modellek válaszai az emberi gondolkodás tökéletlenséget tükrözték.
Projektek O-gyűrűje. Mit tanulhat egy projektvezető a Challenger tragédiájából?