
Miközben az IBM kutatói éppen a legjobb humán vitázót is leérvelő algoritmust simogatnak, kiderült, hogy egy csomó mesterséges intelligenciával foglalkozó projekt alapvetően félremegy azzal, hogy nem kellően pontos adatmintákból dolgoznak.
Alapvető probléma
Az MIT szakemberei az MI tesztelésére, trenirozására leggyakrabban használt adattömegeket vizsgálták meg. Ide olyan készletek tartoznak, amelyeket egyenként is minimum 100 ezer alkalommal vetettek be valamilyen fejlesztés során. Van köztük szöveges alapú, amely például az Amazon áruházából, vagy az IMDb oldaláról származik, de képek tengerét és hangfelvételek sokaságát is vizsgálták azok pontossága, megfelelő felcímkézése szerint.
Összességében 3,4 százaléknyi mintáról derült ki, hogy pontatlanul, vagy éppen teljesen rosszul van azonosítva az eredeti adattömegben. Ez értelemszerűen elég nagy arány ahhoz, hogy jelentősen befolyásolja az ezeken trenírozott algoritmusok eredményességét, pontosságát.
A hibák igen széles spektrumon mozogtak. Az Amazon termékértékeléseinél például pozitívnak lett megjelölve egy sor, egyértelműen negatív vélemény, és ugyanerre fordítva is bőven előfordult. A képek esetében említhető állatok félresikerült azonosítása, de olyan hibák is előfordultak, amikor egy képen nem a fő motívum, hanem egy jelentéktelen részlet lett címkeként rögzítve (egy kerékpárnál például a vázon tartott üditős flakont sikerült kiemelni). A legdurvább találat talán az a cumizó csecsemőt ábrázoló fotó volt, amelyet mellbimbóként sikerült kategorizálni.
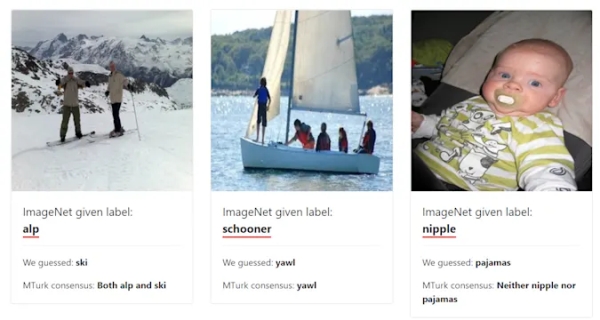
Példák a félrecímkézett fotókra (forrás: MIT)
A szövegek és képek félreértelmezése után azon sincs mit csodálkozni, hogy a hangfelvételeket tartalmazó adatkészleteknél sem stimmelt minden. A YouTube anyagaiból származó csomagnál az egyik említett fiaskó az volt, hogy egy hosszabb beszédet egyszerűen templomi harangszónak azonosítottak (utóbbi egyébként tényleg hallható a felvételen, ám csak a végén és egy rövid ideig).
Kóddal ellenőriztettek (nem hibátlanul)
Mivel hatalmas adattömegekről van szó, így értelemszerűen a kutatók nem tudták ezt a vizsgálatot önerőből elvégezni. Ehhez első körben egy az adatkészletekben meglévő irreleváns információkat kutató keretrendszert vetettek be. Az algoritmus által megjelölt vitás eseteket aztán kiadták bérmunkába az Amazon Mechanical Turk platformján, amelyen az ilyen jellegű egyszerű, de nagy mennyiségű feladatokra lehet jelentkezőket toborozni.
Az eredmények összesítését követően kiderült, hogy a kód által előzetesen kigyűjtött elemek több mint fele valóban nem volt tökéletesen beazonosítva. A QuickDraw elnevezésű tesztkészlet lett a negatív bajnok azzal, hogy az adattömeg nagyjából tizede tekinthető rossznak.
Egyébként hiba és hiba között is komoly különbségek vannak, hiszen a rossznak minősített besorolások egy része inkább csak apró pontatlanságnak, vagy határesetnek tekinthető. Ráadásul gyakran akasztották a hóhért, hiszen a problémákat kutató algoritmusnak is sikerült mellényúlnia: egy esetben például egy teljesen pontosan felcímkézett, hangvillát ábrázoló fotóról azt hitte, hogy menóra van rajta, ezért a hibás csoportba utalta a mintát.
Akik egyébként szeretnének mazsolázni a fentebb említett hibákon túl is, azok mindenképpen látogassák meg a kutatók által erre a célra létrehozott honlapot.
Projektek O-gyűrűje. Mit tanulhat egy projektvezető a Challenger tragédiájából?