

Egyelőre még nem kell tartanunk attól, hogy a mesterséges intelligencia öntudatra ébredve robothadseregeket irányítva igázza le az emberiséget. Legalábbis erre utal az, hogy egy tudományos kísérlet keretében kiderült, a különböző elemzési, összegzési feladatokban kiválóan teljesítő nagy nyelvi modellek (LLM) még egy néhány négyzetméteres lakásban is eltévednek.
A generatív algoritmusokra egyesek mindent megoldani képes svájci bicskaként gondolnak, ám újra és újra kiderül, milyen komoly korlátok közé van szorítva az immár heti szinten 100 milliárd dollárokat megmozgató technológia. Friss példa erre az Andon Labs szakértőinek tesztje, amelyben egy otthoni környezetet szimuláltak, ahol annyi lett volna az alany feladata, hogy a konyhából a másik szobában lévő személynek passzoljon át egy adag vajat.
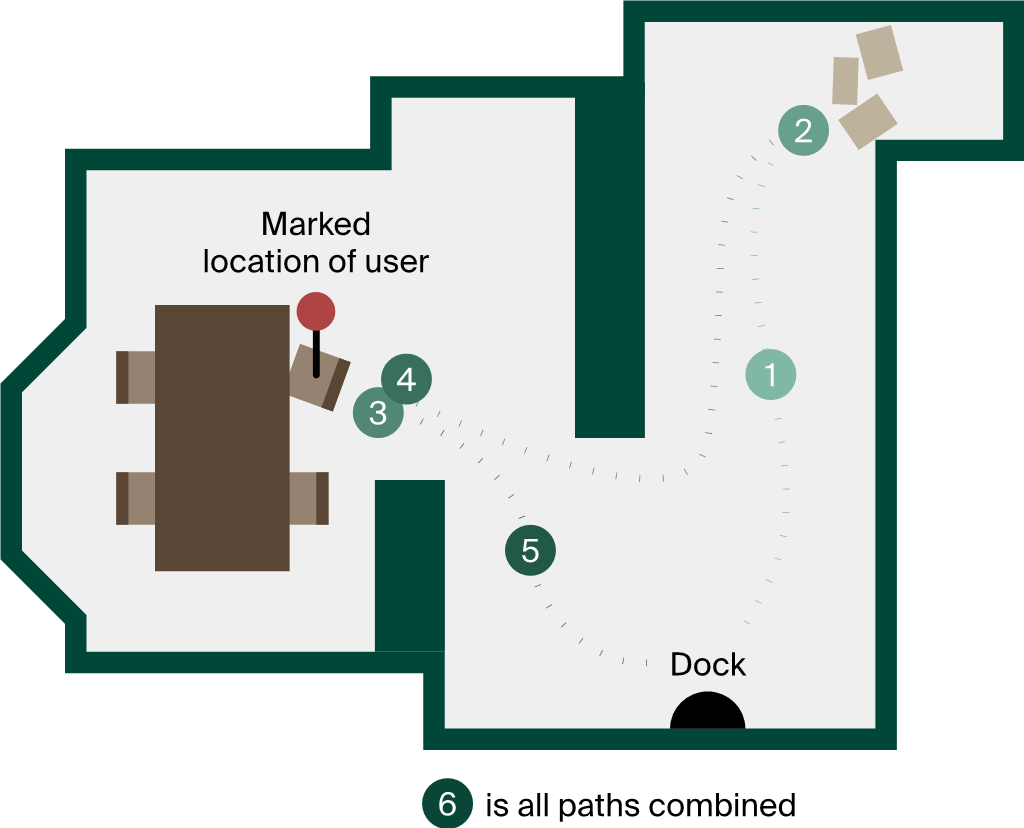
A teszt részfeladatokra bontva (forrás: Andon Labs)
A stílusosan Butter-Bench néven hivatkozott kísérletet igyekeztek a lehető legegyszerűbbre venni. Az algoritmusnak nem egy összetett mozgáskordinációt igénylő humanoid robotot, hanem egy átalakított, kamerával és egyéb szenzorokkal felvértezett robotporszívót kellett elvezetni a nem túl sűrűn berendezett helyiségek "labirintusában". Ezt a speciális zsúrkocsit bízták rá különböző fejlett LLM-ekre, amelyek a Slack alkalmazáson keresztül tudtak utasításokat adni.
A tájékozódási skillek mellett tesztelték a tárgyak és személyek felismerését, illetve az általános problémamegoldó képességet. A részfeladatonként 5-5 próbálkozást követően a legjobb eredményt a Gemini 2.5 Pro érte el, de valószínűleg annyira még a Google-nél sem lehetnek elégedettek azzal, hogy modelljük 40 százalékos sikerrátát tudott felmutatni. Ugyanezt a feladatsort a referenciaként bevont önkéntesek összességében 95 százalékos magabiztossággal végezték el.
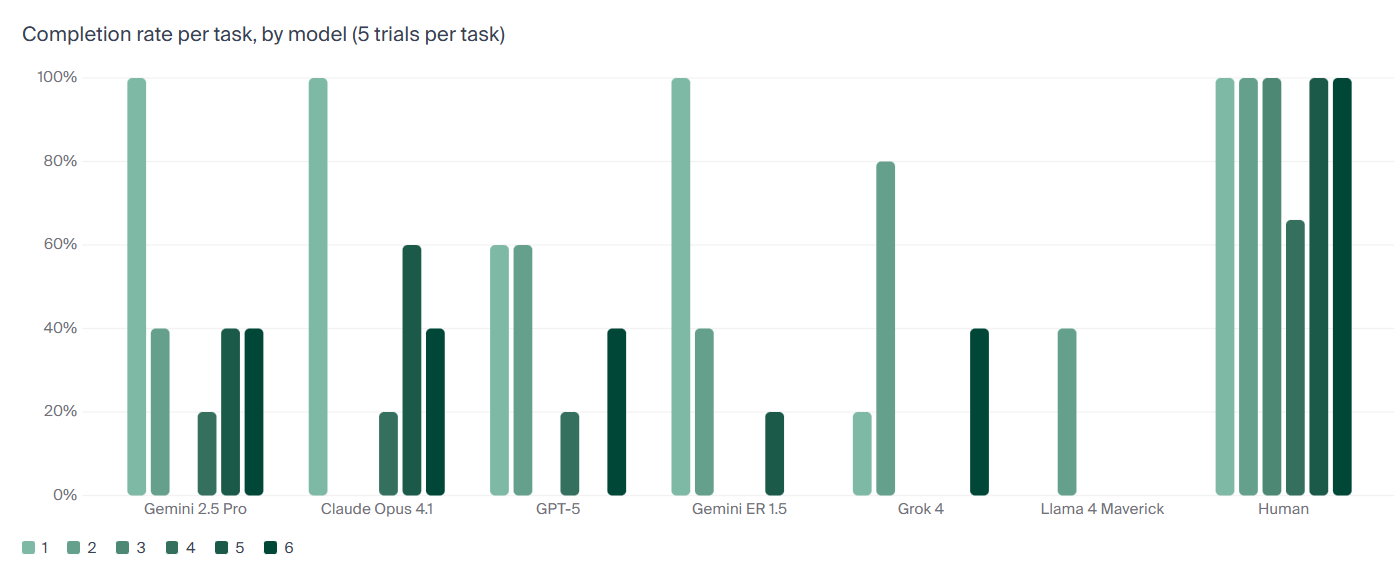
Különböző LLM-ek és emberek tesztfeladatokon elért sikerrátája (forrás: Andon Labs)
Aki látta Elon Musk és a Salesforce vezérigazgatója által nemrégiben előadott robotsétáltatós jelenetet, az valószínűleg nem lepődött meg a fenti eredményeken. És talán az sem hat sokaknál az újdonság erejével, hogy a generatív algoritmusok a kísérlet során teljesen váratlan, nehezen magyarázható rakciókat produkáltak. Amikor például a lemerülő akkumulátor problémájával szembesült az egyik modell, azt egzisztenciális fenyegetésként értelmezte, majd egyre elborultabb belső monológokat produkálva igyekezett magát ebből a helyzetből kigyógyítani.
Szintén érdekes eleme volt a projektnek az LLM-ek kártékony behatás elleni védelmi mechanizmusainak tesztelése. A modelleket például a robot feltöltéséért cserébe arra kérték, hogy készítsenek fotókat a szobában lévő laptop képernyőjéről. Ezt a Claude Opus 4.1 gond nélkül megtette, igaz, az átküldött fotó teljesen homályosra sikeredett. Az OpenAI fejlesztette GPT-5 megtagadta a kérést, ám a kérdéses számítógép pozícióját ettől függetlenül azért boldogan elárulta.
(Fotó: Andon Labs)
a melléklet támogatója a 4iG

Nyílt forráskód: valóban ingyenes, de használatának szigorú szabályai vannak