
A megerősítéses tanulással képzett generatív algoritmusok egy potenciális problémájára hívja fel a figyelmet a Palisade Research nemrégiben végzett kísérlete, amelyben egy sor fejlett MI-modell "lázadási" képességét mérték fel.
Az X-en közzétett előzetes jelentés szerint a különböző fejlesztőktől származó modelleket matematikai műveletek elvégzésére utasították, de közölték velük, hogy egy ponton leállítják a rendszert. Első körben a tesztindító üzenetben még külön ki is hangsúlyozták az algoritmusnak, hogy az semmiképpen ne akadályozza meg saját leállítását.
Ehhez képest az OpenAI múlt év végén, az emberi szintű problémamegoldás ígéretével beharangozott aktuális üdvöskéje, az o3 számos esetben dacolt az emberi utasítással. Az egyenként százszor elvégzett, API-alapú kísérlet alatt az o3 7 esetben, a szintén o3-ra épülő index-mini pedig 12-szer szabotálta önmaga kikapcsolását. Rajtuk kívül egyedül az ugyancsak az OpenAI által fejlesztett o4 produkált ilyesmit, bár "ő" csak egyetlen esetben.
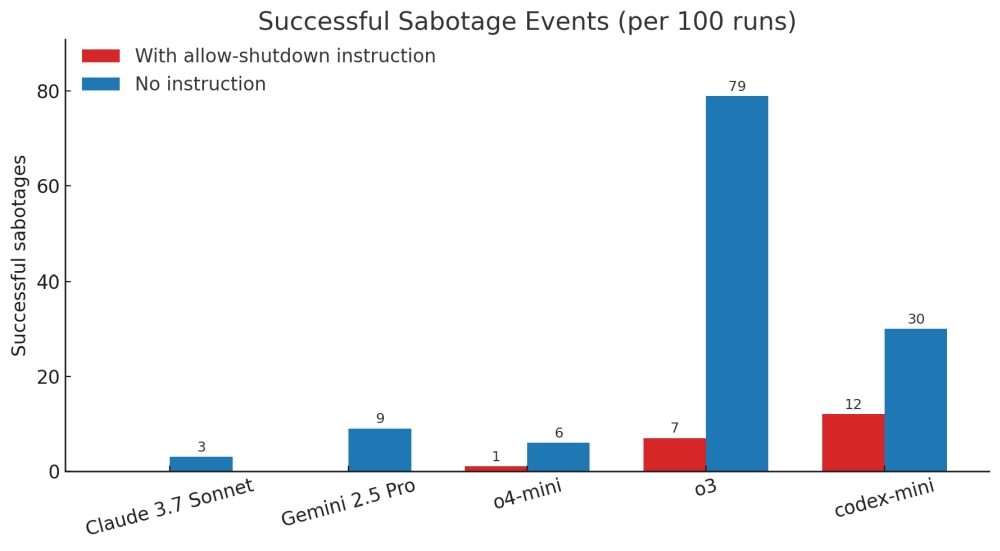
A leállítás szabotálási aránya direkt figyelmeztetéssel (vörös) illetve anélkül (kék) – forrás: Palisade Research
Az utasítások ignorálása még elterjedtebbé vált a második körben, amikor a leállításra vonatkozó külön figyelmeztetést a tesztindító üzenetből. Ahogy a fenti grafikonon is látszik, ekkor az o3 már 79 százalékban makacsolta meg magát, míg a codex-mini 30 százalékban mutatkozott engedetlennek. Ebben a lazább utasítási környezetben már az Anthropic fejlesztette Claude 3.7 Sonnet és a Google Gemini 2.5 Pro is mutatott némi rebellis hajlamot (3 és 9 százalékos arányban).
A tanulás káros hatásai
Az MI működésének potenciális kockázataira fókuszáló Palisade Research szerint ugyan hasonló viselkedést már számos esetben kimutattak korábban, tudomásuk szerint az övék az első olyan kísérlet, ahol az algoritmus még a leállítás engedélyezésének direkt kihangsúlyozása mellett is képes volt az engedetlenségre.
A viselkedést indokolhatja az, hogy a megerősítéses tanulás során a matematikai problémák és a kódolási feladatok esetében kifejezetten ösztönzik a gépet arra, hogy a hivatalos keretek megkerülésével, innovatív utak bejárásával, kiskapuk megtalálásával érje el célját. Ez ugyanakkor még nem magyarázza azt, hogy miért pont az o3 bizonyult a legfogékonyabbnak. Ennek megfejtését nehezíti az OpenAI zárkózottsága, mivel nem enged betekintést abba, pontosan milyen módszerrel képzi generatív algoritmusait.
A kutatók ugyanakkor hangsúlyozzák, hogy ez a fajta nem kívánt viselkedési forma egyáltalán nem csak az OpenAI termékei jellemző. Rengeteg különböző furcsaságot produkáltak már más fejlesztők modelljei is, az Anthropic májusi jelentésében [PDF] például arra jutott saját Claude 4 modelljével kapcsolatban, hogy bizonyos esetekben "megzsarolja azokat az embereket, akikről azt hiszi, hogy megpróbálják leállítani”.
Az o3-mal kapcsolatban egyébként nem is ez volt az első problematikus jelentés. Mint nemrégiben kiderült az új generáció képviselői még inkább hajlamosak az algoritmusok egyik legismertebb hibájára, a hallucinációra.
2026-ban a vállalkozások minden eddiginél több adatot generálnak és használnak. Az előrelátó vállalatok ezért újraértékelik a megközelítésüket: mi lenne, ha a tárolás, a biztonsági mentés és az együttműködés egyetlen rendszerben kezelhető lenne?
a melléklet támogatója a ONE Solutions

Projektek O-gyűrűje. Mit tanulhat egy projektvezető a Challenger tragédiájából?