
Általánosan elérhető a Lyra audiokodek forráskódja, jelentette be tegnap a Google. A vállalat egy ideje már tesztelte a gépi tanulási (ML – Machine Learning) eljárásokat alkalmazó kódolót, többek között a Duo alkalmazásban. Az eddigi tapasztalatok szerint 3 kbit/s sávszélesség mellett már megfelelő hangminőséget ad. Ez óriási előrelépés a hangtovábbítás hatékonyságában. A WebRTC-alapú VoIP (Voice over IP) alkalmazásokban leggyakrabban használt Opus kodeknek ugyanilyen minőséghez például 8 kbit/s kell.
A Google már a tesztek során azt hangsúlyozta, hogy az új audiokodek az AV1-es videotömörítő eljárásukkal együtt már 56 kbit/s-os sávszélesség mellett is használható videocsetre ad lehetőséget. És hogy miért érdekes ez a sávszélesség-korlát a Google számára? A világban még jelentős azok száma (az USA-ban is), akik telefonmodemről neteznek. Az így elérhető átviteli sebesség viszont olyan alacsony, hogy akik ilyen a netelérést használtak, a pandémiás időszakban kiszorultak a videocsetes kapcsolattartás (oktatás, munka stb.) lehetőségéből. Hosszabb távon azonban általánosan is fontos, hogy olyan kommunikációs megoldások szülessenek, melyek takarékoskodnak a sávszélességgel, mivel az adatforgalom gyorsabban nő, mint az átviteli kapacitás.
Mit tesz hozzá a gépi tanulás?
A kodekre azért van szükség, hogy az emberi érzékszervek (jelen esetben a fül) számára felfogható analóg jeleket digitális csatornákon közvetíthető jelekké alakítsa, majd a célállomáson ismét analóggá konvertálja vissza. A hagyományos eljárás a mintavétel módszerével dolgozik, bizonyos sűrűséggel mintát vesz az analóg jelből, és azt valamilyen algoritmussal kódolja, tömöríti. Ebben az esetben – nagyon leegyszerűsítve – ha növeljük a mintavételt, javul a minőség, ám nő a sávszélességigény. Ha csökkentjük, romlik a hangminőség, ám a jel kisebb sávszélességen is célba jut.
A Google más módszert követett. Az alapelv itt is egyszerű: nem mintát vesznek az analóg jelből, hanem megpróbálják elkülöníteni a beszéd egyedi jellegzetességeit, attribútumait, és ezeket vonják ki az analóg hangból 40 ms-onként, majd tömörítik is a továbbításhoz. Innentől persze már bonyolódik a dolog, mert a módszer a hangjellemzőket például ún. log mel spektrogramokként írja le (az eljárás bugyraiba itt lehet megkezdeni az alászállást), és egy mesterségesintelligencia-alapú generatív modellt használ a visszaállításra.
A Lyra kodek működési sémája
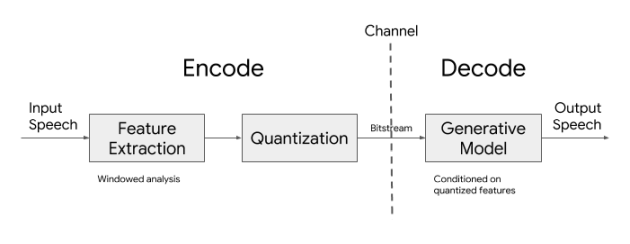
(Forrás: Google)
Mint a Google korábban mesterségesintelligencia-blogjában írta, a folyamat hasonlít az amerikai hadseregnél és a NATO-ban is használt MELP kódolásra, annak hátulütői nélkül. Mivel a MELP esetében mindennél fontosabb, hogy alacsony sávszélesség mellett is átmenjen az információ, a minőség mindaddig lényegtelen, amíg az információ nem sérül (érthető marad a beszéd), tehát az sem számít, ha csak valamiféle robotszerű hang érkezik meg a vevő oldalra. A generatív modell segítségével azonban a Google-nek sikerült élvezhető szintre javítani az átvitt jeleket.
Az ML-modell megalkotásához nagy segítséget jelentettek a Google korábbi kutatása, pl. a DeepMinddal a szöveggenerálás terén elért eredmények. A Líra kodek mögött dolgozó ML-modell tanításához több mint 70 nyelven rögzített több ezer órányi hangfelvételt használtak. Az eredmény egy széleskörűen használható kodek lett, ami lényegében bármilyen, jelenleg használt környezetben működőképes, és a legrosszabb esetben is mindössze 90 ms a késleltetése, állítja a Google.
Vegye-vigye...
A Google a Lyra esetében is az Android modellt követi: nyílt forráskódúvá teszi a kodeket. A fejlesztők kapnak olyan, 64 bites ARM Android platformra optimalizált eszközöket is, amik segítenek a Lyra beépítésében. A tervek között további platformok is szerepelnek.
A kodek Apache licencelésű forráskódja a GitHubon érhető el a matematikai kernel kivételével, de a tervek szerint később abból is lesz nyílt forráskódú változat.
a melléklet támogatója a ONE Solutions

Projektek O-gyűrűje. Mit tanulhat egy projektvezető a Challenger tragédiájából?