
A 2010-ben alapított DeepMind 2014-ben került a Google, utóbb pedig az Alphabet ellenőrzése alá, az amerikaiaknak a hírek szerint több mint félmilliárd dollárjába került a brit mesterségesintelligencia-kutató cég felvásárlása. A DeepMind ambiciózus küldetése, hogy "megfejtse az intelligenciát", vagyis létrehozza a megfelelően hatékony, általános felhasználású tanuló algoritmusokat, egyúttal formalizálja az intelligencia fogalmát, és ezen keresztül segítsen megérteni az emberi elme működését is.
Az elmúlt időben mi is többször beszámoltunk a DeepMind látványos eredményeiről. Így például arról, amikor a deep Q-networknek nevezett algoritmus végigjátszotta a számítógépes őskorszak ikonikus darabjára, az Atari 2600-ra írt félszáz játékot, vagy amikor az ugyancsak a DeepMind által fejlesztett AlphaGo legyőzte az egyik legerősebb profi gójátékost. Kevésbé látványos, de nem kevésbé fontos irány volt az adatközpontok fogyasztásának optimalizálása, a szájról olvasás vagy az életveszélyes betegség kockázatainak kutatása is.
Az AI és a fogolydilemma
A DeepMind házat tájáról származó legújabb érdekesség az az interneten is közzétett belső tanulmány, amelyben a Google tudósai a neurális hálózatok kooperatív és kompetitív viselkedésének vizsgálatáról írnak. A kísérletekben tulajdonképpen arra voltak kíváncsiak, hogy az összetettebb és egyszerűbb algoritmusok az erőforráshiányos környezetekben a versengő vagy az együttműködő megoldásokra lesznek hajlamosak.
Az első játékban a rendszereknek zöld almákat (pixeleket) kellett begyűjteniük egy zárt területen, méghozzá úgy, hogy a gyűjtögetés mellett-helyett egymás megbénítására is lehetőségük volt egy elképzelt lézersugárral. Ahogy a DeepMind lenti videóján is látszik, addig nem volt probléma, amíg elég alma jutott mindenkinek, a zöld pixelek fogyatkozásával azonban egyre gyakrabban rúgta fel valamelyik algoritmus az alapértelmezett tűzszünetet:
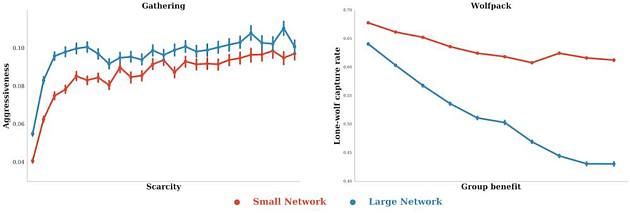
Külön érdekes, hogy a kutatás alapján a kisebb, vagyis praktikusan kevésbé intelligens neurális hálózatok tovább tartották meg a békés és együttműködő viselkedést, míg a nagyobb, bonyolultabb rendszerek a kísérlet során szívesebben támadták meg a vetélytársakat.
A második játékban az algoritmusoknak egy "prédát" (vagyis egy mozgó pixelt) kellett levadászniuk, amit természetesen egyedül is megpróbálhattak, de össze is foghattak, hogy megkönnyítsék a saját dolgukat. A dokumentumban "farkasfalkának" nevezett feladatot ismét csak a nagyobb és összetettebb hálózatok értették meg gyorsabban, és hamar elkezdtek összedolgozni egymással, míg az egyszerűbb versenyzők ebben a számban is felemás eredményeket értek el:
Vagyis minél bonyolultabb neurális hálózatról volt szó, a rendszer annál inkább a saját (természetesen a programozók által meghatározott) érdekeinek megfelelően nyúlt az együttműködés vagy a versengés eszközeihez: a célok eléréséhez alapvetően a kooperációt részesítette előnyben, ahogy azonban az erőforrások szűkössé váltak, nem habozott megtámadni sem a riválisokat.
Anélkül, hogy beszaladnánk a csőbe, és megpróbálnánk az AI-k az emberekéhez hasonló, tanult visedéséből néhány mondatban eljutni a Skynethez, ide másolunk két összehasonlító ábrát az egyszerű és bonyolult rendszerek jellemző döntéseiről (a kép forrása itt is a Google DeepMind részlege):
Projektek O-gyűrűje. Mit tanulhat egy projektvezető a Challenger tragédiájából?