
Hogyan lehet az üzleti adatok és az egyéb, külső forrásokból származó adatok feldolgozásával jobb elemzési eredményekhez jutni? Lényegében erre a kérdésre ad egy választ az SAP napokban bejelentett memóriaalapú lekérdezési motorja, a HANA Vora.
Az új motor lényegében a strukturálatlan adatok OLAP lekérdezésekbe történő bevonására ad megoldást. De nem ez az újdonsága.
Egyszerűsíti az adatkezelést
A cél az volt, hogy az adattudósok és elemzők egyszerűben tudjanak együtt kezelni belső vállalati és Hadoop adatokat. A Vora alapja az Apache Spark keretrendszer, amely kvázi szabvány az iparágban big data elemzésekben, ráadásul szintén memóriaalapú, akárcsak a HANA.
A megoldással azt a problémát próbálta kiküszöbölni az SAP, hogy miközben a Hadoop valóban jó eszköze a big data adatok tárolásának, ám nem igazán gyors az üzleti elemzésekhez. Az vállalat úgy véli, hogy ennek a korlátnak a feloldásában az a jó megoldás, ha összekapcsolja a Hadoopot a memóriaalapú működéssel. A Vora egyébként együttműködik ugyan a HANA-val, de anélkül is használható. A nyílt forráskódú Spark API-ja is nyílt. Programozásához a Spark R vagy ML nyelvet lehet használni, de a Vora más nyelveket is támogat saját Vora-eszközök fejlesztéséhez.
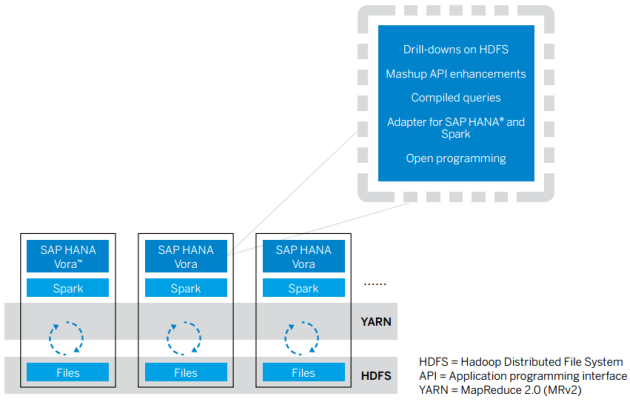
A HANA Vora működési váza (forrás: SAP)
A lekérdező motort helyben telepített és szolgáltatásként használható formában is kínálják, ez utóbbinak lesz ingyenes próbaváltozata az Amazon Web Services-en.
Mit jelent ez az üzletnek?
A Vora segítségével olyan elemzéseket lehet készíteni, amelyek a vállalat működése (gyártás, értékesítés, CRM, ellátási lánc stb.) során keletkezett adatok mellé bevon társadalmi hangulatra, időjárásra vonatkozó adatokat, valamint a közösségi médiából begyűjtött információkat.
Ezek közös elemzésével jó előrejelzések adhatók például arra, hogy az időjárás alakulása vagy a társadalmi hangulat változása hogyan befolyásolja az adott cég üzleti tevékenységét. Maga az SAP konkrét példákat is említ: távközlési hálózatok üzemeltetői például a rendszer segítségével olyan forgalmi mintákat rajzolhatnak ki, melyek ismeretében a kiküszöbölhetők a hálózatban a szűk keresztmetszetek, és javítható a szolgáltatás minősége. Használható csalásfelderítéshez és azzal kapcsolatos kockázatok csökkentéséhez azáltal, hogy a tranzakció- és ügyféltörténeti adatok elemzésével kimutathatók anomáliák. De akár nagy közüzemi infrastruktúrák üzembiztossága is növelhető azáltal, hogy a rendszer szenzorainak az adatai együtt elemezhetők a korábbi karbantartások nyilvántartásaival, hibajegyekkel, anyagszámlákkal stb.
Nagy fegyvertény az open source-nak
Az SAP döntésének jelentősége talán nem is a megoldás újszerűsége. Sokkal inkább az, hogy egy fontos trendre utal: a nagyvállalati piacra fejlesztő cégek egyre kevésbé tudják megkerülni az ezen a piacon sikeres open source kezdeményezéseket.
Az adatelemzés terén a Hadoop és az Apache Spark is kvázi szabványnak számít, amely egyre több támogatót tudhat maga mögött. Ebből azonban az is következik, hogy a hagyományos nagyvállalati piacon dolgozó cégeknek újra kell gondolniuk üzleti modelljüket. Az SAP is lépett ebbe az irányba azzal, hogy erőteljesen elmozdult a felhőszolgáltatások felé. De az nem biztos, hogy elég lesz, számukra is megkerülhetetlen lesz, hogy valamiféleképpen részévé váljanak az open source ökoszisztémának.
2026-ban a vállalkozások minden eddiginél több adatot generálnak és használnak. Az előrelátó vállalatok ezért újraértékelik a megközelítésüket: mi lenne, ha a tárolás, a biztonsági mentés és az együttműködés egyetlen rendszerben kezelhető lenne?
a melléklet támogatója a ONE Solutions

Projektek O-gyűrűje. Mit tanulhat egy projektvezető a Challenger tragédiájából?