
A tényleges eredményességre, a GDP-ben mérhető gazdasági haszonra fókuszáló teljesítménymérő rendszert indított útjára a Kaliforniai Egyetem (Berkeley) kutatócsapata és több mint 300 együttműködő szakértő. Az Agents’ Last Exam (ALE) elnevezésű kezdeményezés lényege, hogy a meglévő, gyakran megtévesztő eredményeket adó, esetleg könnyen manipulálható benchmarkok helyett egy olyan összetett tesztkörnyezetet biztosítson a nagy nyelvi modellekre (LLM) épülő MI-ágenseknek, ahol az ügynököknek valódi teendőket kell valódi munkakörnyezethez hasonló platformon elvégezniük.
Megnehezítik az ügynökök életét
Az ALE kezdetben közel 1500 valódi munkakörökhöz társítható feladatsorral indul, de a távlati cél a portfólió 5000 darabosra bővítése. A benchmark három nehézségi szintbe (Near-Term, Full-Spectrum, Last-Exam) sorolja a munkafolyamatokat. Ezeket úgy lőtték be, hogy a legkönnyebbek egy részével már a jelenleg nyilvánosan elérhető, közepesen erős ágensek is képesek megbirkózni, míg a "végső teszt" esetében egyelőre az is csodaszámba megy, ha egy modell pontot tud szerezni. Utóbbiak már olyan összetett és mély szakmai tudást igényelnek, hogy az ALE megalkotói szerint valamikor 2028 és 2030 között juthatunk el oda, hogy az algoritmusok képesek lesznek az emberekhez mérhető minőségű produkcióra.
Az új teljesítménymérő rendszer kialakításánál különösen figyeltek arra, hogy azt ne lehessen az eddig ismert módokon kijátszani. A korábbi benchmarkok esetében például nagy problémát jelentett, hogy a tesztkérdések egy idő után bekerültek a későbbi modellgenerációk tanítási adatkészletébe, ami miatt az újabb változatok a tényleges képességüknél jobb eredményeket tudtak felmutatni.
Az ALE a fentiek miatt úgy próbál átlátható maradni, hogy közben nem ássa alá a tesztrendszer hosszabb távú integritását. A nyílt forráskódú projekt egyszerre csak adatkészletének nagyjából 10 százalékát teszi elérhetővé. Ez segít a modell fejlesztőinek abban, hogy nagy vonalakban tudják, mire kell számítani a "vizsgán", de nem elégséges ahhoz, hogy a végső eredményt ez érdemben befolyásolja. Különösen úgy nem, hogy a tesztfeladatokat idővel rotálják: a publikus rész elemei kikerülnek a rendszerből, a korábban nem nyilvános munkafolyamatok közül néhány bekerül a szabadon elérhető csoportba, helyüket pedig újakkal töltik fel a szigorúan titkos állományban.
Tolongás a csúcson
Ami a konkrét helyzetet illeti, az igény szerint szűrhető, szűkíthető ranglista összesített változatát 24 százalékos eredményességi mutatóval az OpenAI Codex ügynöke vezeti, amely mögött az fejlesztő áprilisban megjelent GPT 5.5 modellje dolgozik.
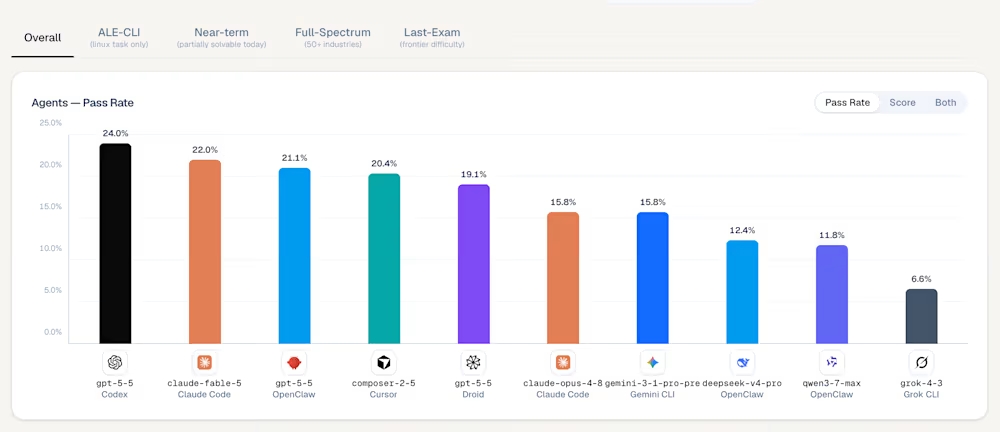
Különböző ügynökök és modellek általános teljesítménye az ALE teszjén (forrás: Agents' Last Exam)
Az Anthropic héten megjelent, Mythos-osztályú Claude Fable 5 modellje ugyan nincs sokkal lemaradva a maga 22 százalékával az élharcostól, ám ez az eredmény így is meglepetésnek számít. Egyrészt az OpenAI riválisa az újdonságait bemutató blogposztban nem győzte sorolni a különböző benchmarkokat, amelyeknél a GPT 5.5 rendre alulmaradt a Fable 5-tel szemben. Másrészt a Mythos-osztály bevezetését megelőzte egy szűk tesztkör, ami arra engedett következtetni, hogy az Anthropic boszorkánykonyhájában valami nagyon erőset sikerült kifőzni.
A cég áprilisban tette elérhetővé néhány megbízható ügyfele – pl. a Google és a nagyobb bankok, köztük a JP Morgan, a Goldman Sachs, a Citigroup, a Bank of America és a Morgan Stanley – számára tesztelési céllal a Mythost. A modell olyan hatékonyan mutatott rá az érzékeny informatikai rendszerekben rejlő sebezhetőségre, hogy az valóságos pánikhullámot váltott ki az amerikai bankrendszerben májusban.
A jelek szerint azonban még minden MI-fejlesztőnél van mit javítani, hiszen a legnehezebb besorolású feladatokat egyelőre a legtöbb ügynök 0 százalékos hatékonysággal képes abszolválni. A legjobb eredménnyel itt is a GPT 5.5 büszkélkedhet, de ebben az esetben is mindössze 2,6 százalékos eredményességi rátáról beszélhetünk.
Szintet lép a Synology: Érkezik a PAS7700 csúcskategóriás vállalati flash tároló
Ahogy a vállalati IT-környezetek az AI-alapú folyamatok, a virtualizáció, a nagy teljesítményű adatbázisok és a folyamatosan elérhető digitális szolgáltatások nyomása alatt fejlődnek, a szervezetek egyre inkább olyan tárolóinfrastruktúrát igényelnek, amely kompromisszumok nélküli teljesítményt, rugalmasságot és skálázhatóságot biztosít.
Projektek O-gyűrűje. Mit tanulhat egy projektvezető a Challenger tragédiájából?