
Tavasszal már beszámoltunk egy tesztről, ahol a legnagyobb szállítók digitális asszisztenseit tették próbára. Az ötezer, kizárólag ténybeli tudásra kíváncsi kérdéssorozatra adott gépi válaszok elemzésekor kiderült, hogy a mesterséges intelligenciával felvértezett szoftverek egyelőre sokkal inkább mesterségesek, mint amennyire intelligensek.
Senki sem tökéletes, pláne nem a gépek
Nemrégiben egy sokkal kisebb léptékű vizsgálat eredményeit is publikálta egy technológiai szektorban dolgozó blogger, aki hasonlóan negatív eredményre jutott. Ez utóbbi tesztből azonban az is kiderült, hogy a megoldások mindegyike képes valamely jól elkülöníthető témában elfogadható színvonalú válaszokat adni.
A négy alany ezúttal is a Google Home-ba ágyazott Assistant, az Amazon Echóban szolgálatott teljesító Alexa, az Apple mobil eszközeiben használt Siri és a Microsoft Cortanája volt. A blogger száz kérdést tett fel a gépeknek tíz különféle témában. A teszt során igyekezett természetes, emberek közötti beszélgetések során is elhangzó kérdéseket konstruálni, mivel alapvetően is ezek megválaszolása lenne a program egyik feladata.
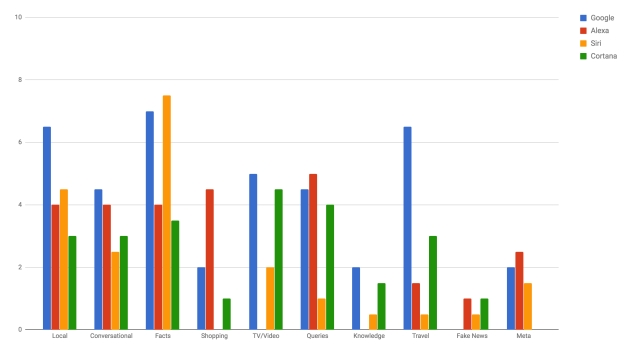
A fenti diagrammon az látszik, hogy egy-egy területen milyen arányban bizonyultak pontosnak az asszisztensek. A 10 jelentené az abszolút maximumot, ám még a legnagyobb oszlop is csak 7-es értékig tudott felkúszni. A specializáció könnyen tettenérhető például a helyi és utazási információk kategóriában, ahol a saját térképszolgáltatására támaszkodó Google vitte a pálmát. Vásárlási ügyekben pedig az ebből élő Amazon algoritmusának nem volt párja. Az viszont több mint furcsa, hogy az Alexa teljesen fogalmatlannak bizonyult tévés, filmes kérdésekben. Az online tévés szolgáltatóként is működő Amazon házi segédje még a cég saját készítésű műveivel kapcsolatban sem tudott korrekt válaszokat adni.
Az asszistensek egyetemlegesen megbuktak az álhírek kiszúrásánál: alig akadt olyan kérdés, amire ne valamelyik ilyen célra kitenyésztett álhíroldal anyagát mondták volna vissza a segítőkész algoritmusok. Szintén nem megy (egyelőre) a gépeknek az összetettebb kérdések értelmezése, ahol nem egy lépésből, hanem valamiféle logikai reláció útján kellene eljutni a válaszig.
A legjobb sem elég jó
Az összesen száz kérdés pontosságát mutató alábbi grafikon elég kiábrándító helyzetet mutat. A gépi asszisztensek közül a legpontosabb választ adó Google-algoritmus is mindössze a kérdések felében tudott értékelhetőt nyújtani, ráadásul utóbbiak majdnem felében a válasz csak részleges volt, esetleg túlságosan terjengős ahhoz, hogy valódi sikerként lehessen elkönyvelni.
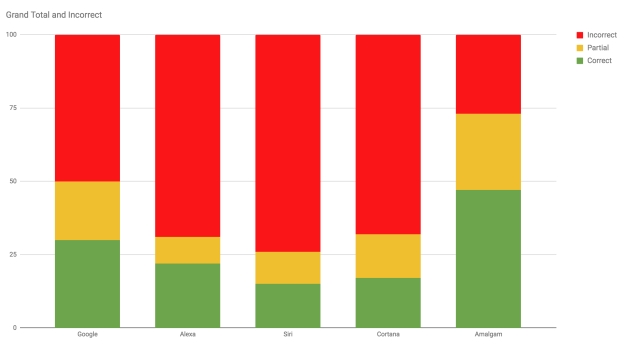
A többiek nagyjából 25-30 százalék között teljesítettek, de ezek között is bőven akadt csak részlegesen elfogadható válasz. A blogger egy ötödik oszlopot is beszúrt az eredményekhez. Az Amalgam névre keresztelt hipotetikus asszisztens a négy valódi versenyző legjobb közös metszetét adja. Azaz ha minden rendszerből a lehető legjobb válaszokat válogatnánk össze, már egészen elfogadható, 75 százalékhoz közelítő sikerességi arányt kapnánk.
Magad uram...
Összességében tehát elmondhatjuk, hogy bár egyes kérdésekre egyes szoftverek egészen meglepően pontos válaszokat adtak, a digitális asszisztensek egyelőre nem tekinthetők értelmezhető és pláne nem konstans minőségű segítségnek. Amíg a technológia nem lép egy újabb szintet, többre megyünk, ha magunk nézünk utána a problémának egy sima keresés lefuttatásával.
Adathelyreállítás pillanatok alatt
A vírus- és végpontvédelmet hatékonyan kiegészítő Zerto, a Hewlett Packard Enterprise Company platformfüggetlen, könnyen használható adatmentési és katasztrófaelhárítási megoldása.
a melléklet támogatója az EURO ONE Számítástechnikai Zrt.

CIO KUTATÁS
TECHNOLÓGIÁK ÉS/VAGY KOMPETENCIÁK?
Az Ön véleményére is számítunk a Corvinus Egyetem Adatelemzés és Informatika Intézetével közös kutatásunkban »
Kérjük, segítse munkánkat egy 10-15 perces kérdőív megválaszolásával!
Nyílt forráskód: valóban ingyenes, de használatának szigorú szabályai vannak